Анализ времени выполнения запроса в параллельном
колоночном
хранилище…
3
Каждая колонка, хранимая на диске, разделена на блоки опреде-
ленного размера
b
S
. Блок состоит из заголовка, размер которого пре-
небрежительно мал по сравнению с размером блока и непосред-
ственно данных. При одном запросе к диску осуществляется чтение
нескольких блоков, количество которых определяется параметром.
Каждой записи в столбце относится ее позиция (номер строки).
В большинстве современных колоночных БД [14] значения столбца
упорядочиваются по их позициям.
На логическом уровне колоночные и строчные СУБД идентичны,
т. е. способны обрабатывать одни и те же SQL-запросы. Но отличия в
физической организации хранения данных существенно влияют на
реализацию процессов, связанных с формированием плана выполне-
ния запроса и его реализацией.
В строчных СУБД план запроса представляет собой дерево, у
каждого узла которого имеется один родитель и один (или два в слу-
чае пересечения) дочерних узла. Реализация исполнителя планов ба-
зируется на следующих трех базовых парадигмах [15]: синхронный
конвейер, итераторная модель, скобочный шаблон.
Более подробно изменения, вносимые в каждый из перечислен-
ных элементов плана, рассмотрены в работах [11, 15].
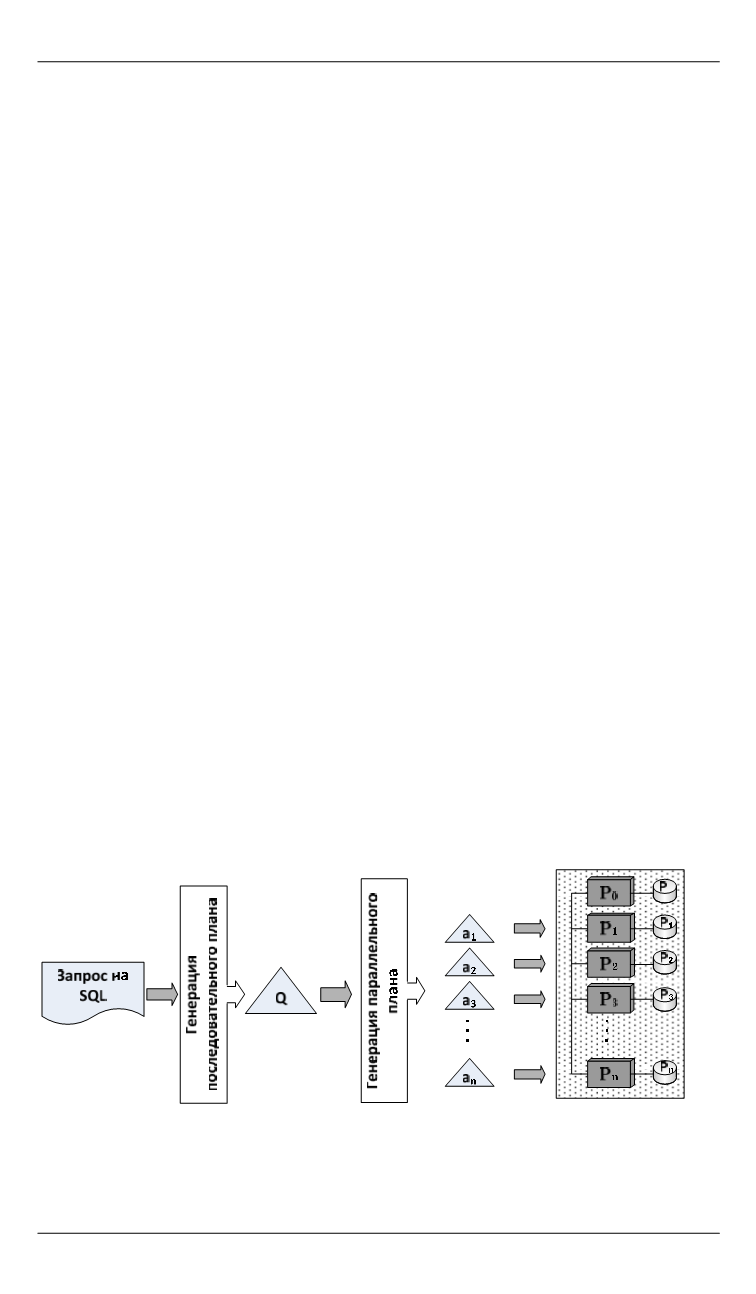
Организация параллельной обработки данных.
Основная
форма параллельной обработки запросов в строчных и колоночных
СУБД — фрагментный параллелизм. Подробно данный процесс рас-
смотрен в работах [2–4, 16]. В соответствие с этой схемой запрос на
языке SQL преобразуется в некоторый последовательный план, кото-
рый, в свою очередь, преобразуется в параллельный план, представ-
ляющий собой совокупность
n
идентичных параллельных агентов,
которые реализуют те же операции, что и последовательный план
(рис.1).
Рис. 1.
Генерация параллельного плана запроса


