Ю.А. Григорьев, Е.Ю. Ермаков
4
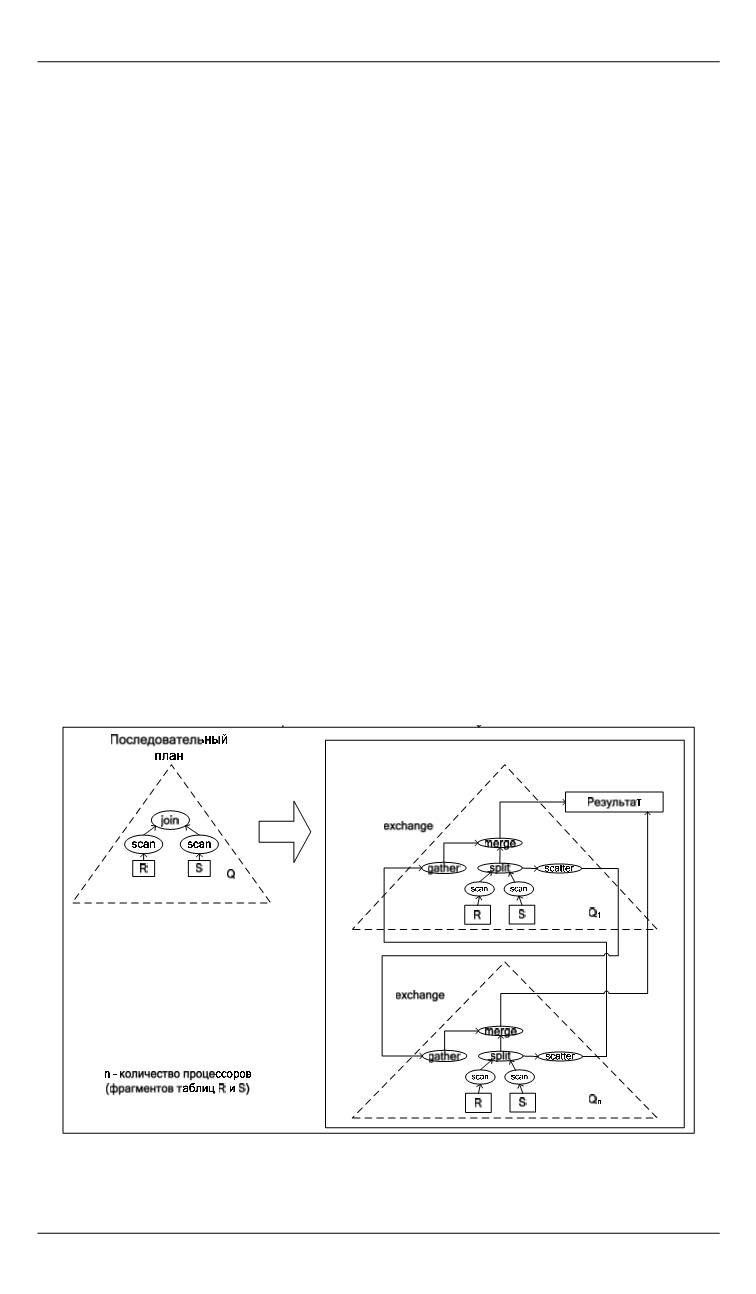
Здесь
n
обозначает количество процессорных узлов. Это дости-
гается путем вставки в соответствующие места дерева плана запро-
са составного оператора exchange, состоящего из четырех
операторов: split, gather, merge и scatter. На завершающем этапе
агенты рассылаются на определенные процессорные узлы, где ин-
терпретируются исполнителем запросов. Результаты выполнения
агентов объединяются корневым оператором exchange на нулевом
процессорном модуле.
Рассмотрим процесс параллельной обработки запроса, где выполня-
ется соединение таблиц
R
и
S
базы данных (рис. 2).
Q
=
R
S
— это
логическая операция соединения (join) двух отношений (таблиц)
R
и
S
по некоторому общему атрибуту
Y
. В данном примере таблица
R
фраг-
ментирована произвольным образом, а таблица
S
— по атрибуту соеди-
нения
Y
. На рис. 2 показано, что логический план выполнения соедине-
ния двух отношений тиражируется на
n
процессоров в параллельной
системе баз данных (ПСБД) (на рисунке показаны два процессора). Да-
лее происходит параллельная обработка на каждом процессоре соответ-
ствующих фрагментов таблиц
R
и
S
. Вследствие того, что таблица
R
не
фрагментирована по атрибуту соединения, при последовательном чте-
нии записей этой таблицы происходит их обработка в операторе ex-
change, осуществляющем разбор записи и ее межпроцессорный обмен.
Таблица
S
фрагментирована по атрибуту соединения, и записи, читае-
мые из фрагментов этой таблицы, обрабатываются на каждом процес-
соре локально.
Рис. 2.
Обработка запроса
Q
=
R
S
в параллельной системе баз данных


